引言
大多数 AI Agent 项目死于同一个原因。
不是因为模型不够聪明,也不是因为工具不够多——而是根本没有 Harness。Harness 是让 Agent 行为可预测、可观测、可恢复的那一层工程基础设施。没有它,Agent 就是个黑盒子,跑起来全靠运气。
我最近认真读了 DeerFlow 2.0 的源码,它在 Harness Engineering 上给出了一套完整的工程答案。六个技术域,每一个都有明确的设计决策和代码实现。
在逐个讲清楚之前,我放几张我对Prompt Engineering、Context Engineering、Harness Engineering几个阶段的理解:
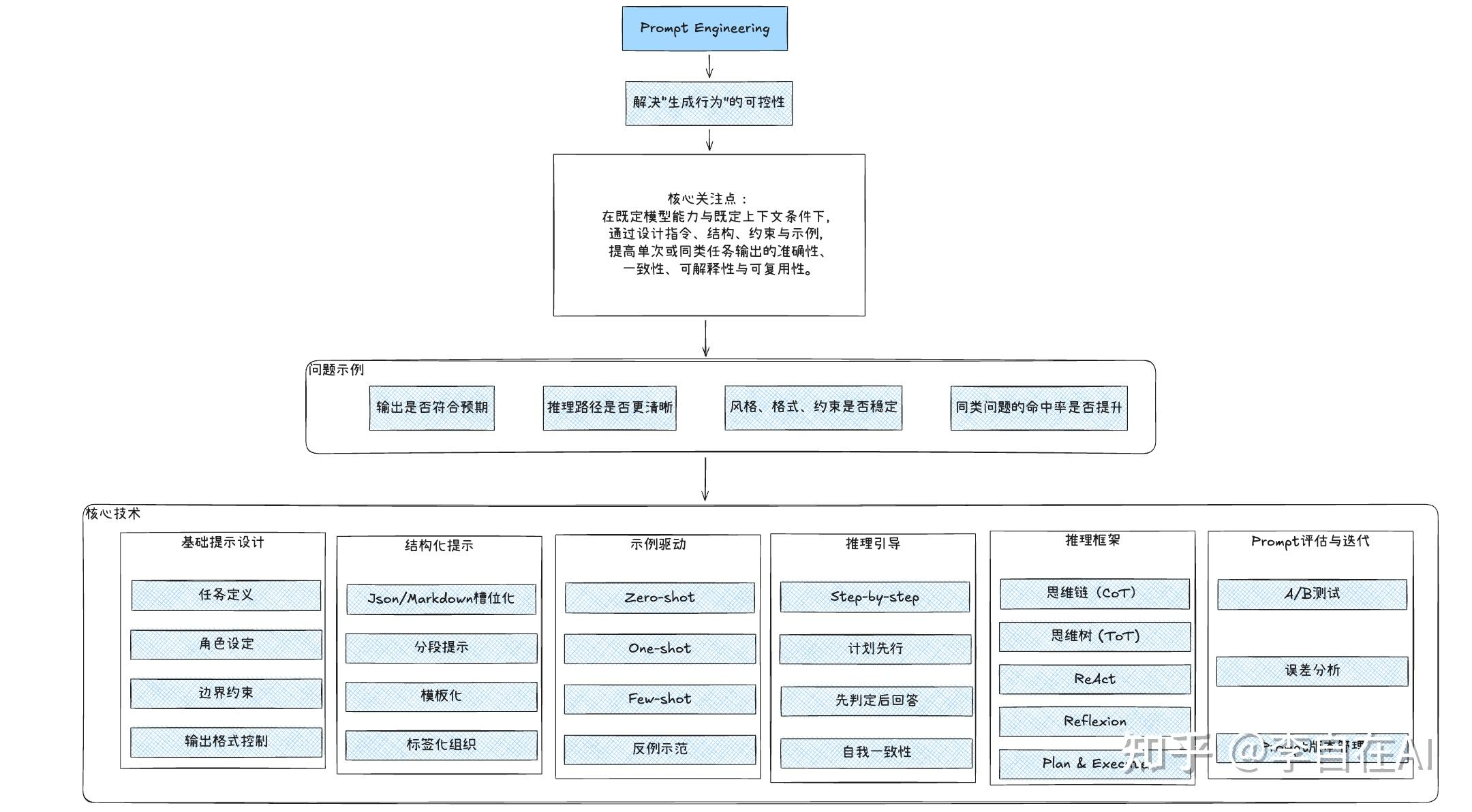
Prompt Engineering
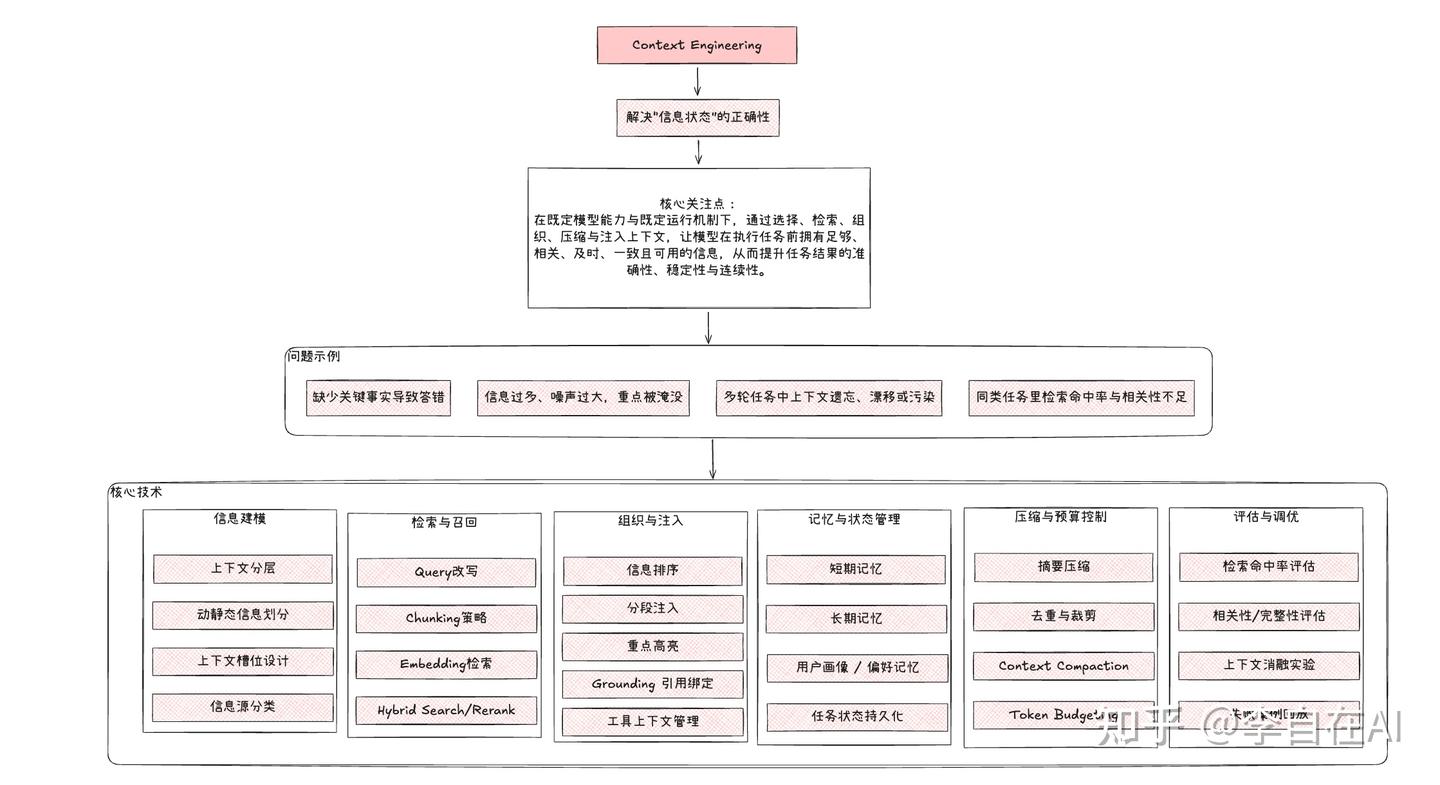
Context Engineering
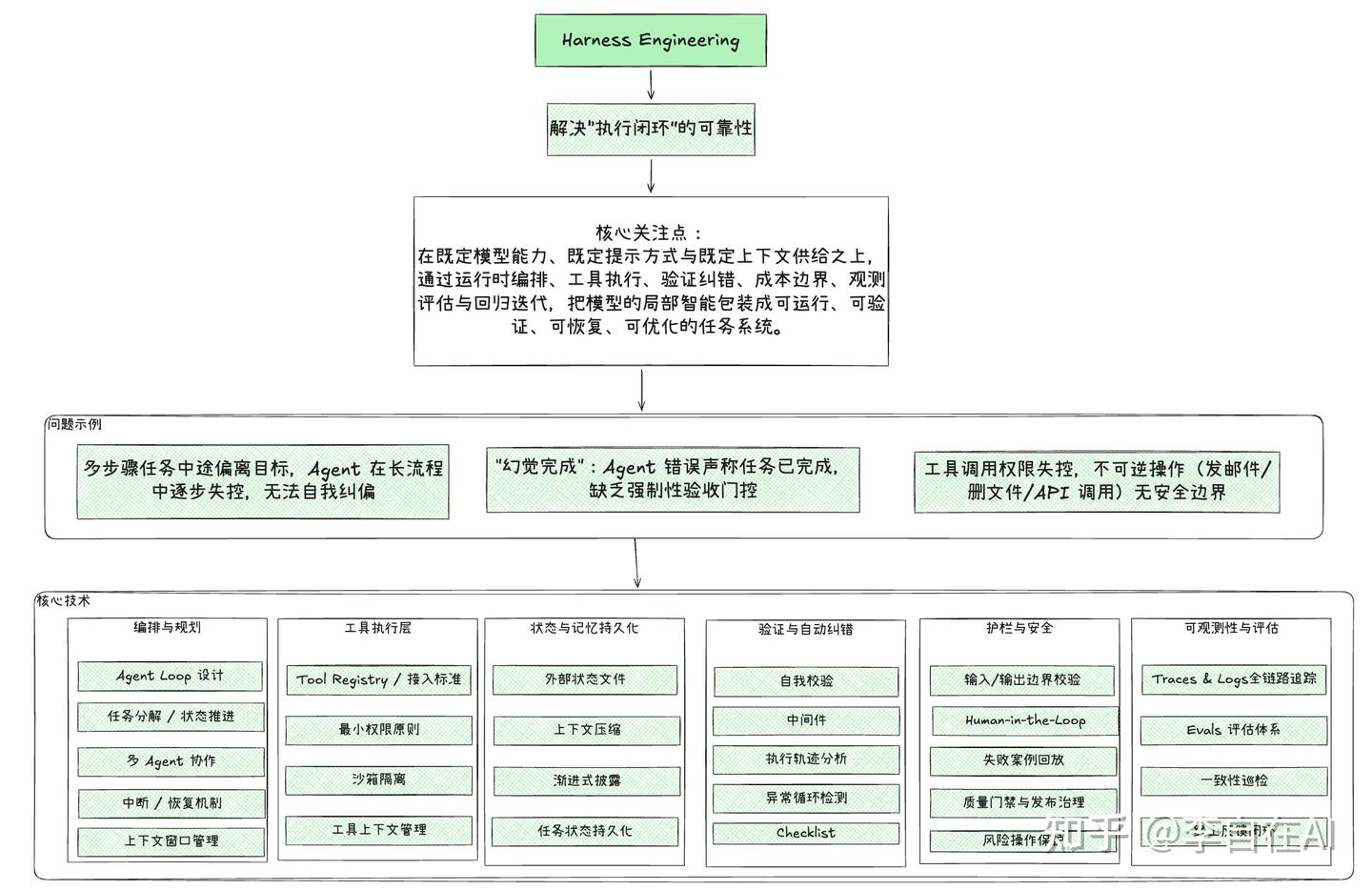
Harness Engineering
编排与规划
是什么?
编排(Orchestration)是指将一个复杂的用户目标拆解为多个子任务,并协调多个专职 Agent 按正确的顺序、依赖关系和条件分支完成这些任务的机制。规划(Planning)是 Agent 在执行前或执行中对任务路径进行思考和调整的过程。
核心子技术
Supervisor 模式(多 Agent 协调)
Supervisor 是一个"元 Agent",接收用户目标、分解子任务、为每个子任务选择合适的专职 Agent、监控执行结果并在失败时重新调度。
Planning Loop(规划循环)
Agent 在执行过程中持续"计划 → 执行 → 观察 → 调整",与 ReAct(Reasoning + Acting)框架一致。
条件路由与重路由策略
Harness 需要预定义成功路径、失败路径、超时路径,形成可预测的执行图。
Handoff 协议(Agent 间交接)
当一个 Agent 将任务移交给另一个 Agent 时,需要明确传递当前任务的完成状态、已收集的上下文信息、以及对下一个 Agent 的具体指令。
DeerFlow 是怎么做的?
LeadAgent + Subagent 的双层架构
DeerFlow 采用的是 LeadAgent(主 Agent) + Subagent(子 Agent) 的双层结构。LeadAgent 不是一个独立的调度节点,而是在自己的 ReAct 循环中直接发起子 Agent 调用:
用户目标
│
▼
LeadAgent(主推理循环)
├─ 直接处理简单任务(LLM 直接回答)
├─ 调用 bash / write_file / web_search 工具
└─ 调用 task 工具 → 派发 Subagent
├─ Subagent A(general-purpose)
├─ Subagent B(bash 专项)
└─ Subagent C(自定义 Agent)
这个结构通过 LangGraph 的 StateGraph 实现。task 工具负责 Handoff 协议,将任务指令、上下文和文件路径通过 ThreadState.messages 传递给子 Agent,子 Agent 完成后将结果写回同一 thread_id 的消息历史。
规划循环由 LangGraph StateGraph 驱动
LeadAgent 的 ReAct 循环完全基于 LangGraph 的有向图:
用户消息进入
│
▼
LLM 推理节点(generate_response)
│
├─ 无 tool_calls → 输出答案,循环结束
│
└─ 有 tool_calls → 工具执行节点(execute_tools)
│
└─ ToolMessage 写回 state.messages → 返回推理节点
每次 LLM 调用都能看到完整的历史 ToolMessage("观察结果"),从而实现 Observe → Reflect → Plan 的完整 ReAct 循环。
System Prompt 中嵌入规划优先级约束
DeerFlow 在 lead_agent/prompt.py 的 System Prompt 中用强制性语言硬编码规划优先级,确保行为可预测:
WORKFLOW PRIORITY: CLARIFY → PLAN → ACT
1. FIRST: 在思考中分析请求,识别不清楚、缺失或模糊的地方
2. SECOND: 如果需要澄清,立即调用 ask_clarification,不要开始执行
3. THIRD: 所有澄清解决后,再规划和执行
CRITICAL RULE: Clarification ALWAYS comes BEFORE action.
这与 Anthropic 的"先确认再执行"原则完全一致,将规划约束从"期望的 LLM 行为"提升为"被代码强制执行的规则"。
工具与环境控制
是什么?
工具(Tools)是 Agent 与外部世界交互的接口,包括代码执行器、搜索引擎、数据库、API 等。环境控制是指对这些交互进行隔离、限制和管理的机制。没有环境控制的 Agent 就像一个拥有 root 权限的程序——可以做任何事,也可以破坏任何事。
核心子技术
沙箱隔离(Sandbox)
Agent 执行代码或操作系统命令时,必须在隔离环境中运行。沙箱的核心价值:Agent 的错误不能扩散到宿主系统。
MCP 工具集成与权限边界
MCP(Model Context Protocol) 以统一方式调用任何外部服务,每个工具声明自己需要的最小权限集合。
最小权限原则
Agent 只申请当前任务所需的最小权限,优先选择可逆操作,当指令不明确时主动询问而非猜测。
工具上下文管理
根据当前任务阶段动态注入相关工具,在工具不再需要时及时移除,减少上下文干扰。
DeerFlow 是怎么做的?
三层沙箱隔离架构
DeerFlow 设计了一套完整的沙箱 Provider 体系,根据安全需求分为三个层级:
| Provider | 隔离方式 | 适用场景 |
|---|---|---|
LocalSandboxProvider | 虚拟路径翻译,无进程隔离 | 受信任的本地开发环境 |
AioSandboxProvider(LocalContainerBackend) | 独立 Docker 容器 | 标准生产部署 |
AioSandboxProvider(RemoteSandboxBackend) | k3s Pod + NodePort 服务 | 大规模生产集群 |
在 Docker 部署时(DooD 模式),每个 thread_id 单独对应一个 all-in-one-sandbox 容器:
宿主机 Docker Daemon
├── deer-flow-langgraph 容器(主进程)
│ └── 挂载 /var/run/docker.sock → 调用宿主机 Docker API
│ └── 创建 deer-flow-sandbox-{sha256(thread_id)[:12]} 容器
└── deer-flow-sandbox-{id}(沙箱容器,进程+文件系统完全隔离)
├── /mnt/user-data/workspace ← Volume 挂载到宿主机对应 thread 目录
├── /mnt/user-data/outputs ← Volume 挂载到宿主机对应 thread 目录
└── /mnt/skills ← 只读挂载 Skills 目录
工具组(Tool Groups)实现最小权限
DeerFlow 通过 tool_groups 机制实现类 RBAC 的权限边界:
# config.yaml
tool_groups:
- name: web # 网络类工具:web_search、web_fetch
- name: file:read # 只读文件:read_file、ls
- name: file:write # 写文件(更高权限):write_file、str_replace
- name: bash # Shell 执行(最高权限)
自定义 Agent 通过 tool_groups 字段按需声明权限集合,LeadAgent 只向该 Agent 注入其有权访问的工具列表。
懒加载沙箱(Lazy Sandbox Init)
SandboxMiddleware 默认 lazy_init=True——沙箱容器不在对话开始时创建,而是在首次调用文件/命令工具时才 acquire:
纯 LLM 推理对话 → 零沙箱槽位占用
首次调用 bash → 触发 _ensure_sandbox() → acquire → 冷启动容器(约 2-5 秒)
同 thread 后续 → 复用同一容器(热路径,毫秒级)
10 分钟无活动 → idle_checker 自动销毁容器,释放资源
MCP 工具集成与延迟加载
DeerFlow 内置 MCP 标准支持,config.yaml 中可声明任意 MCP Server,工具自动注入工具列表。当 MCP 工具数量较多时,tool_search 功能(延迟工具加载)让工具名称只作为索引存入 System Prompt,Agent 按需通过 tool_search 工具检索具体工具,避免大量工具描述占用 Token 上下文。
虚拟路径系统(沙箱安全边界)
所有文件操作工具的路径都经过 _validate_path() 的确定性校验。Agent 只能访问 /mnt/user-data/ 命名空间内的路径,任何试图访问 /etc/、/root/ 等系统路径的操作在工具层被直接拒绝,错误以结构化 ToolMessage 返回,迫使 Agent 修正路径后重试。
状态与记忆持久化
是什么?
LLM 本质上是无状态函数——每次调用只能看到当前上下文窗口里的内容,没有跨会话的原生记忆。状态与记忆持久化技术解决的是:如何让 Agent 在长任务、多轮对话、多会话甚至多天的工作流中保持连贯性,不丢失目标,不重复劳动,不忘记已经做过的决策。
核心子技术
外部状态文件
将 Agent 的工作进度存储在模型外部(文件系统、数据库),而非依赖上下文窗口内的隐式记忆。
Context Compaction(上下文压缩)
随着对话变长,上下文窗口逐渐被历史信息填满(Context Rot)。通过滚动摘要、关键事件提取、分层记忆等策略压缩历史。
渐进式信息披露(Progressive Disclosure)
给 Agent 先提供目录(索引),Agent 按当前任务需要主动检索具体细节,而不是一次性把所有信息塞入上下文。
任务状态持久化与跨会话连续性
Agent 每次启动时先读取外部状态文件,知道"上次做到哪了",实现类似人类的工作记忆。
DeerFlow 是怎么做的?
LangGraph Checkpointer:对话状态的数据库
每一轮对话的完整状态(ThreadState,包含所有 messages、sandbox_id、artifacts 等字段)都通过 LangGraph Checkpointer 持久化到数据库。支持三种后端:
# config.yaml
checkpointer:
type: sqlite # 开发/单进程环境
connection_string: checkpoints.db
# type: postgres # 多进程生产环境
# connection_string: postgresql://user:password@localhost:5432/deerflow
用户断开连接、进程重启、容器重新部署后,下次对话时 LangGraph Server 从 Checkpointer 完整恢复 ThreadState,Agent 无需重新"理解"之前做过的所有事情。
Memory:事实抽取型长期记忆
DeerFlow 实现了一套事实抽取型全局记忆机制(memory.json):
MemoryMiddleware在每次对话结束后分析消息内容- 用 LLM 提取出用户偏好、项目约定等关键事实
- 将事实以结构化方式持久化存储
- 在下次对话的 System Prompt 中注入,形成跨会话的"长期记忆"
通过 fact_confidence_threshold(默认 0.7)、max_facts(默认 100)、max_injection_tokens(默认 2000)等参数控制记忆质量和注入量,防止低置信度事实污染上下文。
SummarizationMiddleware:对话历史自动压缩
DeerFlow 内置 SummarizationMiddleware,当对话超过 Token 阈值时自动触发 LLM 摘要压缩:
# config.yaml
summarization:
enabled: true
trigger:
- type: tokens
value: 15564 # 超过此 Token 数时触发
keep:
type: messages
value: 10 # 保留最近 10 条原始消息,其余压缩为摘要
压缩后的摘要作为 SystemMessage 插入历史,Agent 既能看到当前对话,也不会丢失关键历史背景,对应"滚动摘要"策略。
Skills 的渐进式加载(Progressive Disclosure)
DeerFlow 的 Skills 系统是渐进式信息披露的典型工程实现:
- 仅注入目录:
get_skills_prompt_section()只将 Skills 的名称、描述、路径注入 System Prompt(数百 Token) - 按需加载:当用户请求匹配某 Skill 时,Agent 调用
read_file("/mnt/skills/ppt-generation/SKILL.md")读取完整指令(数千 Token) - 执行时才占满上下文:4 步骤的详细流程只在实际执行时进入上下文
这与"先看目录,再翻到具体章节"的人类查阅文档方式一致,在功能完备的前提下最小化 Token 消耗。
TodoMiddleware:任务进度外部化
TodoMiddleware 将 Agent 的 TODO 列表作为 ThreadState 的一部分持久化。Agent 执行过程中维护的任务进度被写入 Checkpointer,跨会话恢复后 Agent 能准确知道"第几步做完了,接下来做什么"。
验证与确定性约束
是什么?
这是 Harness Engineering 中最关键的可靠性保障机制:通过非 AI 的确定性方法来验证 AI 的输出结果。Agent 可以"幻觉完成"——声称任务已完成但实际上并没有。确定性约束是强制性的验收门控,任务必须通过这些检查才能被标记为完成,而不是靠 Agent 的自我声明。
LLM 决定做什么;确定性系统决定它是否真的做到了。
核心子技术
自动化测试门控
Agent 提交的输出必须通过一系列机器验证(Linter、类型检查、单元测试),否则被强制打回。
输出 Schema 强制校验
对于结构化输出,Harness 在调用结果返回前强制校验格式,避免后续流程因格式不符而崩溃。
架构约束(确定性 linter)
通过确定性规则引擎检查代码或操作是否符合约束,而不是让 LLM 自我评判。
验证循环(错误反馈重试)
测试失败后,Harness 将结构化的错误信息返回给 Agent,触发修复循环,超过重试上限则升级为人工处理。
DeerFlow 是怎么做的?
Pydantic Schema 强制工具入参
DeerFlow 所有工具函数都通过 Pydantic + LangChain 工具框架 在执行前自动校验入参。LLM 如果生成了格式不符的 tool_call 参数(如类型错误、缺少必填字段),直接在工具层抛出 ValidationError,错误信息作为 ToolMessage 写回对话历史,Agent 在下一轮自动修正并重试。
路径合法性校验(确定性 Linter)
sandbox/tools.py 中对所有文件操作施加了确定性的三重路径校验,完全不依赖 LLM 判断:
def _validate_path(virtual_path: str, allow_write: bool) -> str:
# 规则1:必须在允许的命名空间内
if not any(virtual_path.startswith(p) for p in ALLOWED_READ_PATHS):
raise PathNotAllowedError(f"Path '{virtual_path}' is not in allowed paths")
# 规则2:写操作只允许在 outputs 和 workspace
if allow_write and not any(virtual_path.startswith(p) for p in ALLOWED_WRITE_PATHS):
raise PathNotAllowedError("Write access denied outside outputs/workspace")
# 规则3:路径穿越检测(防止 ../../../etc/passwd 攻击)
if ".." in virtual_path.split("/"):
raise PathNotAllowedError("Path traversal detected")
任何违规都返回结构化错误消息给 Agent,Agent 必须修正后重试,不能绕过。
SandboxAuditMiddleware:命令安全分类引擎
每条 bash 命令在沙箱执行前经过正则分类引擎(确定性规则,非 LLM 评判):
| 分类 | 示例命令 | 处理结果 |
|---|---|---|
block | rm -rf /、curl url | bash、dd if= | 返回错误 ToolMessage,不执行,Agent 必须换方案 |
warn | pip install xxx、chmod 777、apt install | 执行,结果中附加 ⚠️ 警告,LLM 知晓风险 |
pass | 正常命令 | 直接执行 |
这是"LLM 决定做什么,确定性系统决定该不该做"架构分离的典型体现。
ClarificationMiddleware:执行前的强制信息门控
当信息不完整时,ask_clarification 工具配合 ClarificationMiddleware 强制中断执行:
Agent 发现信息缺失 → call ask_clarification(question, options)
│
ClarificationMiddleware 拦截(在工具执行前)
│
Command( update={"messages": [ToolMessage(格式化的问题)]},
goto=END ← 当前 run 立即终止,永不执行实际操作 )
│
LangGraph Checkpointer 保存完整 thread 状态
│
用户回答 → 下一轮 run 恢复,Agent 有了所需信息,继续执行
这在代码层面强制执行了"不确定时停下来问,而不是猜测继续"的原则。
Guardrails 与安全
是什么?
Guardrails(护栏)是一套在 Agent 执行过程中持续运行的安全检查机制,防止 Agent 做出有害的、错误的或超出授权范围的行为。
- 验证约束关注输出的正确性(代码能不能跑)
- Guardrails关注行为的安全性(Agent 该不该这么做)
核心子技术
输入/输出边界校验
防止外部数据通过工具调用注入恶意指令(Prompt Injection),并在 Agent 最终输出到达用户或系统前检查内容合规性。
Human-in-the-Loop(HITL 检查点)
在关键决策节点——不可逆操作、低置信度决策、影响范围超出预设边界时——插入人类审批步骤,让人类注意力聚焦在真正需要判断的事情上。
不可逆操作拦截与确认
将所有操作分为可逆(直接执行)、低风险不可逆(执行 + 记录)、高风险不可逆(需人工确认)、危险操作(强制 HITL)四个级别。
失败案例回放与分析
当 Guardrails 触发时,记录完整的执行上下文,构成"失败案例库"用于持续改进 Guardrails 规则。
DeerFlow 是怎么做的?
可插拔的 Guardrails Provider 体系
DeerFlow 提供了开放的 Guardrails Provider 插件系统,支持内置、OAP 标准和自定义三种模式:
# config.yaml
# 1. 内置 AllowlistProvider(工具黑名单,零依赖)
guardrails:
enabled: true
provider:
use: deerflow.guardrails.builtin:AllowlistProvider
config:
denied_tools: ["bash", "write_file"] # 禁止特定工具
# 2. OAP(Open Agent Passport)标准接入任意合规检查服务
guardrails:
enabled: true
provider:
use: aport_guardrails.providers.generic:OAPGuardrailProvider
# 3. 自定义 Provider(任意实现了 evaluate/aevaluate 接口的类)
guardrails:
enabled: true
provider:
use: my_package:MyGuardrailProvider
每一次工具调用在执行前都经过 guardrails.evaluate(tool_call) 检查,放行或阻止,Agent 无法绕过。
ask_clarification + ClarificationMiddleware 实现 HITL
DeerFlow 的 Human-in-the-Loop 通过 ask_clarification 工具覆盖 5 种风险场景,低风险走 Guardrails 自动放行,高风险强制走 HITL:
clarification_type: Literal[
"missing_info", # 缺失必要信息
"ambiguous_requirement", # 需求模糊,多种合法解读
"approach_choice", # 多方案需用户选择技术路径
"risk_confirmation", # ⚠️ 危险操作,需明确确认
"suggestion", # Agent 有建议,需用户批准再执行
]
System Prompt 用强制性语言规定:危险操作前必须调用此工具;Middleware 层通过 goto=END 在工具体执行前强制中断,确保人类介入。
LocalSandbox 安全边界默认关闭 Bash
当用户使用 LocalSandboxProvider(命令直接在宿主机执行),DeerFlow 在 security.py 中默认禁用 bash 执行:
def is_host_bash_allowed(config=None) -> bool:
if uses_local_sandbox_provider(config):
return bool(getattr(sandbox_cfg, "allow_host_bash", False))
# ↑ 默认 False
return True # AioSandbox 有容器隔离兜底,直接放行
Agent 调用 bash 时收到明确错误消息和安全建议,防止在未意识到风险的情况下让 Agent 在宿主机任意执行命令。
多租户路径隔离
不同用户的 thread_id 对应不同的 Volume 挂载路径与不同的沙箱容器,在文件系统层实现完整的用户间隔离:
/host/deer-flow-home/
├── threads/thread-userA-xxx/user-data/ ← 用户 A 的沙箱 Volume
└── threads/thread-userB-yyy/user-data/ ← 用户 B 的沙箱 Volume,完全隔离
即使 Agent 在沙箱内执行任意命令,也无法访问其他用户的数据目录。
可观测性与评估
是什么?
可观测性(Observability)是让开发者能够理解 Agent 内部发生了什么、为什么失败的能力。评估(Evaluation / Evals)是系统性衡量 Agent 输出质量的方法。
没有可观测性,调试 Agent 就像在黑盒里摸索;没有 Evals,你不知道改动是让系统变好了还是变差了。
LangChain 2025 年报告显示:近 90% 的团队已经在追踪 Agent 的 Traces,但 Evals 的采用率仍然偏低——这是当前 Agent 工程最大的短板之一。
核心子技术
Traces & Logs(全链路追踪)
每一次 Agent 执行都应产生完整可追溯记录,包括时间戳、工具调用输入输出、Token 消耗、每次路由决策及原因。
Evals 评估体系
从正确性(对比黄金答案)、相关性(LLM-as-Judge)、完整性(检查清单)、安全性(对抗测试)、效率(Token/耗时)多维度系统性打分。
垃圾回收与一致性巡检
随着 Agent 持续工作,定期运行专门的检查 Agent,发现并修复知识库、文档和代码之间的不一致("熵增")。
失败信号处理与持续再架构
当 Agent 失败时,不只修复那一次输出,而是把失败作为信号——分析缺少什么能力,将缺失能力编码进 Harness。
DeerFlow 是怎么做的?
TokenUsageMiddleware:Token 消耗追踪
内置 TokenUsageMiddleware 对每次 LLM 调用记录 input/output/total token 数量,通过 config.yaml 一行开关:
token_usage:
enabled: true # 每次 LLM 调用在 info 日志中输出 Token 统计
SandboxAuditMiddleware:操作审计日志
每条 bash 命令生成结构化 JSON 审计记录,形成可回放的操作历史:
{
"timestamp": "2026-04-02T10:30:00Z",
"thread_id": "a1b2c3d4",
"command": "python generate_ppt.py",
"verdict": "pass"
}
被 block 的高危命令、medium-risk 命令都产生 WARNING 级别日志,构成安全审计链路。
LangGraph Traces 天然集成
DeerFlow 运行在 LangGraph Server 上,每个 run 的完整执行轨迹(节点进出、状态变化、工具调用详情)由 LangGraph 框架自动记录。通过设置 LANGCHAIN_TRACING_V2=true 和 LangSmith 配置,即可获得完整的可视化 Trace:
Trace: thread-a1b2c3d4 / run-xxx
├── [00:00.000] lead_agent → generate_response
│ └── LLM call: model=doubao-seed-2-pro, input=1240 tokens
├── [00:02.100] execute_tools → bash
│ ├── input: "python /mnt/skills/ppt-generation/generate_ppt.py"
│ └── output: "SUCCESS: output/report.pptx generated"
├── [00:03.500] execute_tools → present_files
│ └── artifacts: ["/mnt/user-data/outputs/report.pptx"]
└── [00:03.520] lead_agent → END (total: 1580 tokens)
SSE 流式输出作为面向用户的实时 Trace
DeerFlow 通过 LangGraph 的 SSE 流将 Agent 的每一步推理过程实时推送给前端,用户可以看到:
- 思考链(
reasoning_content,<think>标签内容) - 工具调用过程(
assistant:processing消息组,显示调用了哪些工具及结果) - 澄清请求(
assistant:clarification消息组,突出显示问题和选项) - 最终答案(
assistant消息组,清晰的 Markdown 回答)
这本质上是将 Agent 内部 Trace 以用户友好的形式实时可视化,让用户有"看到 Agent 在想什么"的透明感。
LoopDetectionMiddleware:无效循环检测
LoopDetectionMiddleware 检测 Agent 是否陷入无意义的重复循环(如反复调用同一工具但结果无变化),超过阈值时强制打断并返回结构化错误,防止 Agent 在无法完成任务时无限消耗 Token。这是一种基于行为模式的确定性检测,构成最低层的"保底"可靠性保障。
总结:六大技术域的关系
┌─────────────────────────────────────────────────────────────┐
│ 用户目标 │
└────────────────────────────┬────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 1. 编排与规划 │
│ LeadAgent + Subagent 双层,LangGraph StateGraph 驱动循环 │
│ CLARIFY→PLAN→ACT 硬编码优先级,task 工具实现 Handoff 协议 │
└────────────────────────────┬────────────────────────────────┘
│
┌──────────────┼──────────────┐
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ LeadAgent │ │ Subagent A │ │ Subagent B │
└─────┬──────┘ └─────┬──────┘ └─────┬──────┘
│ │ │
└───────────────┼───────────────┘
│
每个 Agent 执行时,以下机制同时运行:
│
┌──────────────────┼──────────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│2. 工具与 │ │3. 状态与 │ │4. 验证与 │
│ 环境控制 │ │ 记忆持久化 │ │ 确定性约束 │
│ AioSandbox │ │ Checkpointer │ │ 路径校验引擎 │
│ 容器隔离 │ │ Memory 事实 │ │ 命令安全分类 │
│ Tool Groups │ │ 摘要压缩 │ │ Pydantic校验 │
│ MCP 集成 │ │ Skills懒加载 │ │ Clarification│
└──────────────┘ └──────────────┘ └──────────────┘
│ │ │
└──────────────────┼──────────────────┘
│
┌──────────────────┼──────────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐
│5. Guardrails │ │6. 可观测性 │
│ 与安全 │ │ 与评估 │
│ Provider插件 │ │ Token 追踪 │
│ HITL 澄清 │ │ Audit Log │
│ 路径隔离 │ │ SSE 实时流 │
│ bash 安全门 │ │ 循环检测 │
└──────────────┘ └──────────────┘
三句话记住 DeerFlow 的 Harness 核心:
- 编排:LeadAgent 用 LangGraph ReAct 循环驱动,
task工具完成 Handoff,System Prompt 硬编码 CLARIFY→PLAN→ACT 规划优先级 - 工具 + 状态:AioSandbox 容器隔离保证"做不坏宿主机",Checkpointer + Memory + 摘要压缩保证"跨会话记得住"
- 验证 + Guardrails + 可观测性:路径校验/命令分类做"确定性守门人",ClarificationMiddleware 实现 HITL,LangGraph Traces + SSE 流让执行过程完全透明
*代码依据:DeerFlow 2.0 源码 · backend/packages/harness/deerflow/ · backend/app/ · *frontend/src/core/

